목표
CANoe에서 사용 가능한 UI에 대해서 시간을 들여서 좀 더 상세히 확인
제작
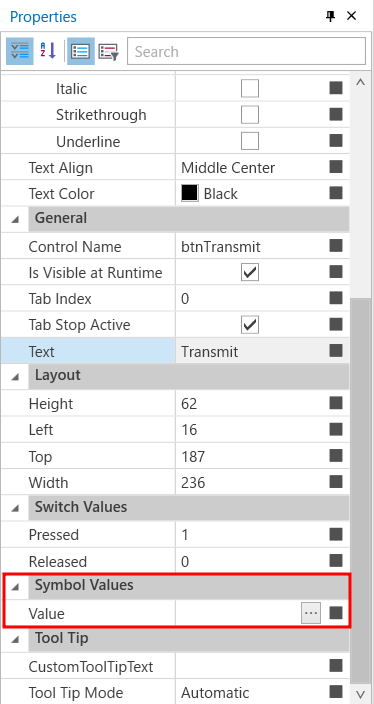
1. System Variable제작

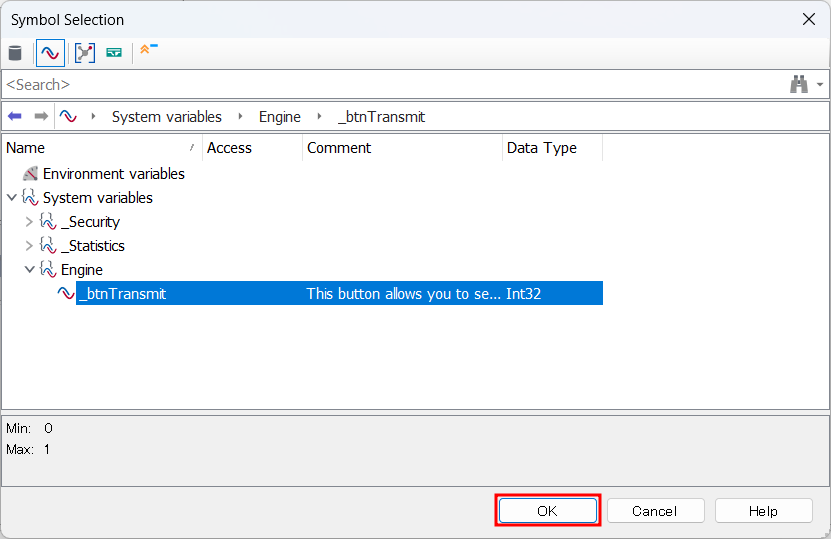
2. Input/Output Box를 드래그해서 제작 후, Property설정 후 System Variable 연결

3. 코드 제작 후 실행 확인
/*@!Encoding:65001*/
on start {
// Initialize the CAN address when the program starts
AdjustCANAddress();
}
on sysvar sysvar::Engine::_btnTransmit {
// Buffer to store the CAN address (maximum 8 characters + null terminator)
char canAddress[9];
// Check if the button is pressed
if(@this == 1) {
// Retrieve the current CAN address
GetCANAddress(canAddress);
// Print the CAN address when the button is clicked
write(":: Current CAN Address: %s", canAddress);
}
}
// This event triggers when the CAN address input field changes
on sysvar sysvar::Engine::_txtCANAddress {
// Adjust the CAN address whenever it is modified
AdjustCANAddress();
}
// Function to adjust the CAN address
void AdjustCANAddress() {
// Buffer to hold the input CAN address (temporary storage)
char buffer[128];
// Buffer to store a valid CAN address (max 8 characters + null terminator)
char limit[9];
// Retrieve the current CAN address value from the system variable
sysGetVariableString(sysvar::Engine::_txtCANAddress, buffer, elcount(buffer));
// If the input field is empty, set a default CAN address
if(strlen(buffer) <= 0) {
sysSetVariableString(sysvar::Engine::_txtCANAddress, "18DA01F1");
}
// If the input exceeds 8 characters, truncate it to 8 characters
else if(strlen(buffer) > 8) {
// Copy only the first 8 characters
mbstrncpy(limit, buffer, 8);
// Update the system variable with the trimmed address
sysSetVariableString(sysvar::Engine::_txtCANAddress, limit);
}
}
// Function to retrieve the adjusted CAN address
void GetCANAddress(char buffer[]) {
AdjustCANAddress(); // Ensure the CAN address is properly formatted
// Retrieve the adjusted CAN address from the system variable
sysGetVariableString(sysvar::Engine::_txtCANAddress, buffer, elcount(buffer));
// Ensure the string is properly null-terminated
buffer[strlen(buffer)] = '\\0';
}

'Programming > CANoe' 카테고리의 다른 글
| CANoe UI 만들기: 버튼 (0) | 2025.03.10 |
|---|---|
| CANoe 함수: mbstrncpy (0) | 2025.03.10 |
| CANoe 함수: strlen (0) | 2025.03.10 |
| CANoe 함수: sysSetVariableString (0) | 2025.03.10 |
| CANoe 함수: sysGetVariableString (0) | 2025.03.02 |

RIsN